機能要件定義書
1. モデル診断カルテページ
以下の項目に沿って要件を定義します。
a. 画面構成
1つのページですが長いため、ここでは3分割にしております。
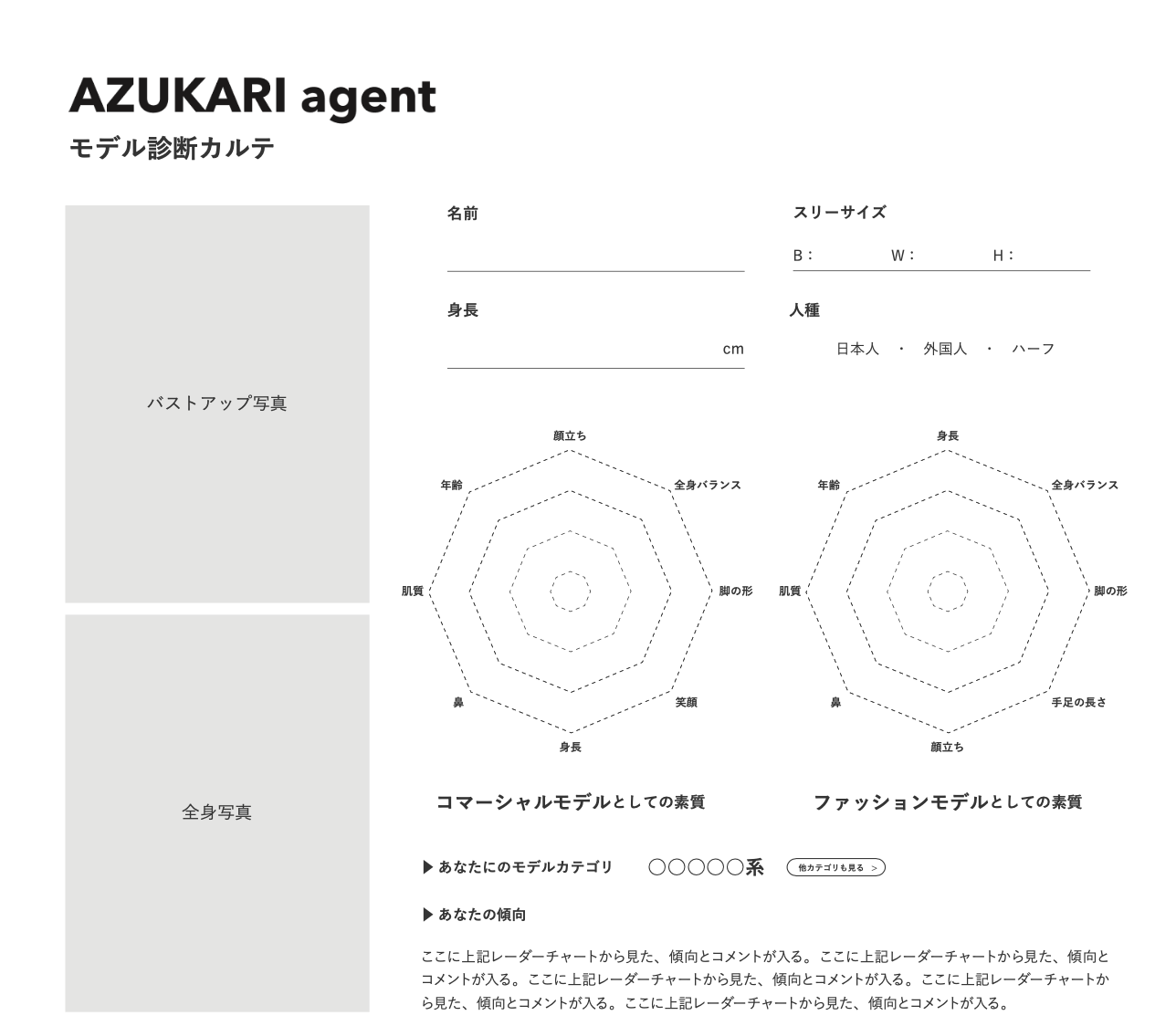
一. 応募者の基本情報・レーダーチャート、傾向など
| ID | 項目 | 説明 |
|---|---|---|
| 1 | ヘッダー | サイト名(例:モデル診断カルテ) |
| 2 | 応募者情報 | 応募者の名前、身長、スリーサイズ、人種、及び応募画像3枚(バストアップ、全身、真横) |
| 3 | レーダーチャート | コマーシャルモデルとしての素質、ファッションモデルとしての素質と称して、2つのモデルカテゴリーの持つ8項目別の得点(基準点)と応募者のモデルの得点を比較した数値(%, 同値の場合は100%)をそれぞれレーダーチャートとして表示させます。 |
| 4 | おすすめのモデルカテゴリー | いくつか存在するモデルカテゴリー(例:ナチュラル系ファッションモデルなど)の中から、応募者の形に近い、得点を持つモデルカテゴリーを一つ算出し、名前とリンクを表示させます。 |
| 5 | あなたの傾向 | モデルカテゴリーの持つ8項目別の得点と応募者のモデルの得点を比較した数値(%)の中から、パーセンテージの高い(=)項目上位3つに関して、予めデータベースで定義していたテキストを表示させる。 |
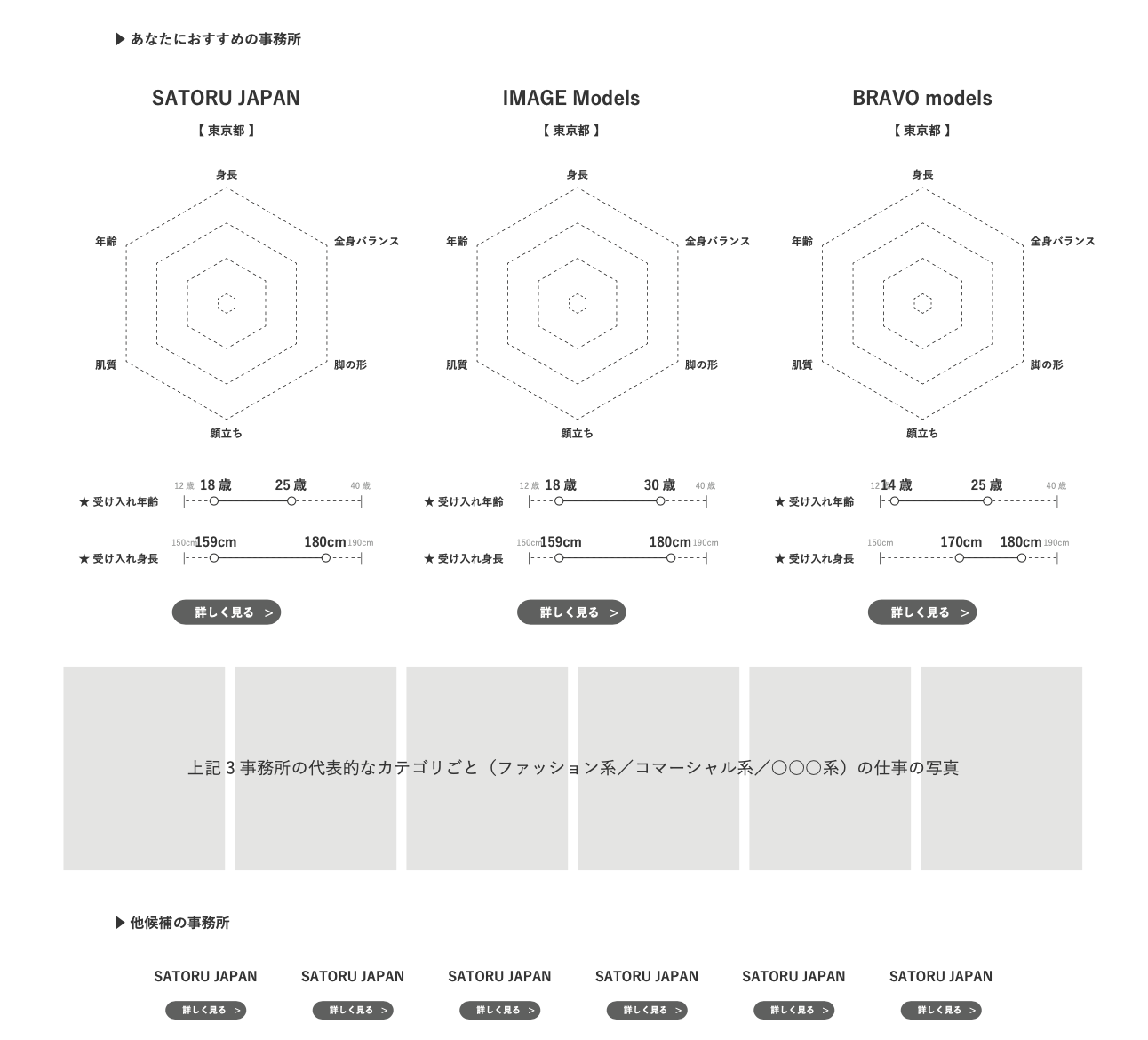
ニ. おすすめの事務所
| ID | 項目 | 説明 |
|---|---|---|
| 1 | 改善ポイントとアドバイス | 上記1のレーダーチャートの際に算出した、モデルカテゴリーの持つ8項目別の得点と応募者のモデルの得点を比較した数値(%)の中から、基準点との乖離が低い方に大きい項目を2つピックアップし、予めデータベースにて定義していた「改善点の見出し」「改善点の詳細文」「参考記事URL」をそれぞれ表示させる。 |
三. 改善ポイントとアドバイス
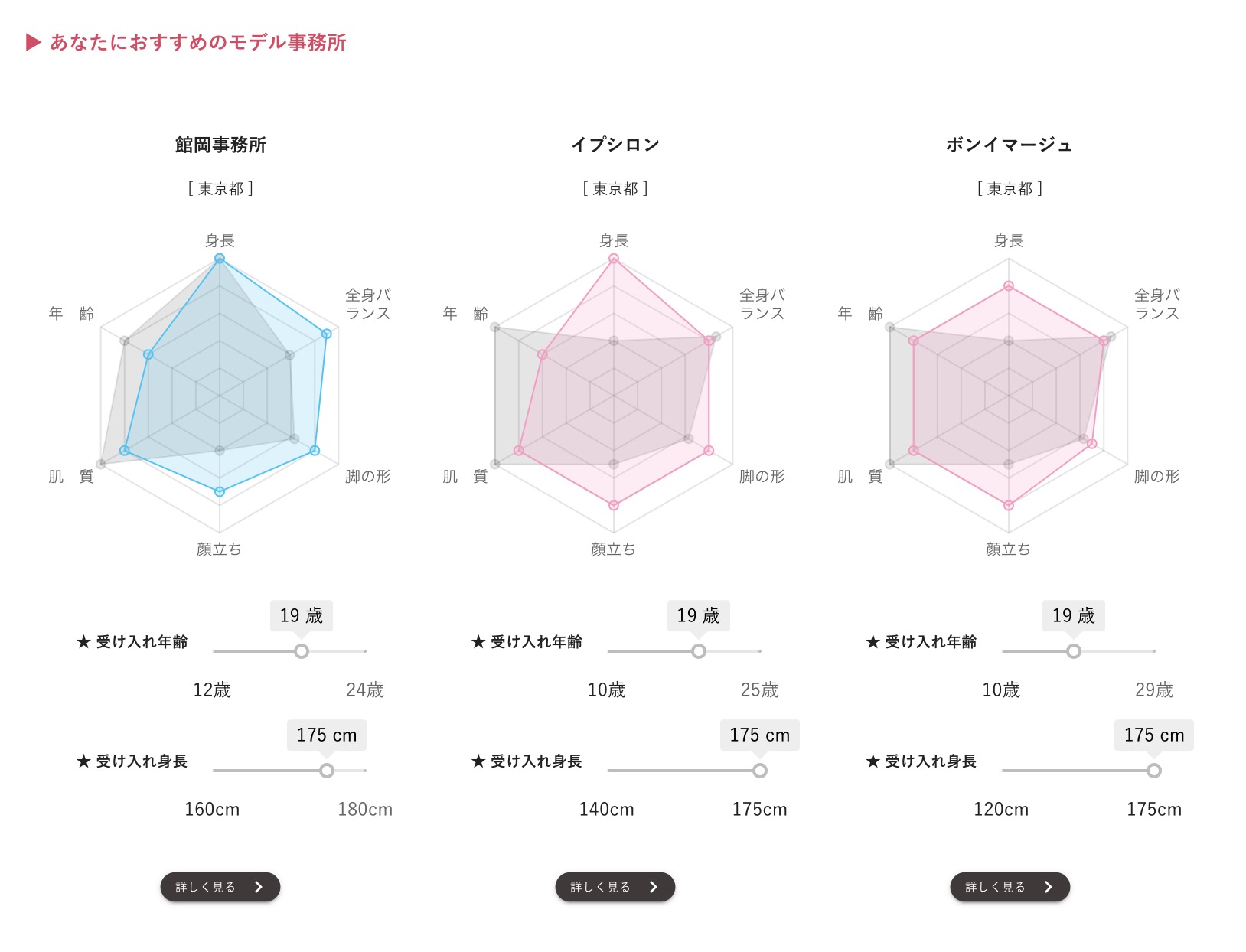
おすすめのモデル事務所の選定方法
b. レーダーチャート算出方法
一. 前提(業務要件)
- 応募者のレーダーチャートは8項目から成り立ちます。
- また、モデルカテゴリーに応じて比較対象となる8項目が一部異なります。
- (具体例:ファッションモデルでは「手足の長さ」、コマーシャルモデルでは「笑顔」。それ以外の7項目は同じです。)
- 項目は同じでも、モデルカテゴリーによって、得点の算出方法は異なります。
- (例えば、コマーシャルモデルでは身長が165cm〜170cmの需要は多いが、ファッションモデルでは身長が175cm以上が望まれるため、モデルカテゴリーごとで同じ身長の項目でも応募者の得点は異なります。)
参考資料)
二. レーダーチャートを表示するまでのデータの流れ
- モデル診断カルテの表示に際し、応募者がデータベース上で予め持っておく値は、「モデルカテゴリーごとの得点」ではなく、応募者の「基本情報」「特性」とし、診断カルテページにアクセスしたタイミングで、採点項目(ファッション)採点項目(コマーシャル)の計算方法をもとに各項目ごとに得点を算出します。
- 算出された応募者の得点(数値)は、データベースに格納された複数のモデルカテゴリーの得点(基準点)と比較され、各項目ごとにパーセンテージが算出されます。
(抜粋)モデル診断カルテページのシーケンス図
三. 応募者情報の定義
応募者の得点の算出に必要な「応募者情報」を以下に定義します。
応募者情報の定義
- 得点の算出には不要な情報
- 応募者名(テキスト)
- 人種(テキスト)
- 登録日時(日時)
- 更新日時(日時)
- 得点の算出に必要な情報
- 生年月日=年齢(日時)
- 身長(数値)
- バスト(数値)
- ウェスト(数値)
- ヒップ(数値)
- 頭身(単一選択)
- 脚の長さ (単一選択)
- 脚の形(単一選択)
- 脚のバランス(単一選択)
- 膝下の長さ(単一選択)
- 手の長さ(単一選択)
- 顔の種類(単一選択)
- 目のタイプ(単一選択)
- 目の形(単一選択)
- 鼻筋(単一選択)
- 鼻の大きさ(単一選択)
- 唇の厚さ(単一選択)
- 口の大きさ(単一選択)
- 先天的要因(複数選択)
- 鼻の比率(数値)
- 鼻の形(複数選択)
- 肌質(複数選択)
歯の特徴(複数選択)→ (要確認:笑顔のバストアップ画像が必要?)笑顔の形(複数選択)→ (要確認:笑顔のバストアップ画像が必要?)
詳細は、データベース設計に記載。
c. 応募者情報の取得方法
上記の応募者情報は、以下の3つの方法により取得します。
- 手動入力
- Google Vision API
- 独自の機械学習モデル
c-1. 手動入力により取得する応募者情報
注記
- 年齢(生年月日)
- 身長
- バスト(数値)
- ウェスト(数値)
- ヒップ(数値)
c-2. Google Vision APIにより取得する応募者情報
以下の画像から各パーツの座標が取得できるため、座標から計算を行います。




注記
- 頭身(単一選択)
- 鼻の比率(数値)
c-3. 独自の機械学習モデルにより取得する応募者情報
注記
- 脚の長さ(単一選択)
- 脚の形(単一選択)
- 脚のバランス(単一選択)
- 膝下の長さ(単一選択)
- 手の長さ(単一選択)
- 顔の種類(単一選択)
- 目のタイプ(単一選択)
- 目の形(単一選択)
- 鼻筋(単一選択)
- 鼻の大きさ(単一選択)
- 唇の厚さ(単一選択)
- 口の大きさ(単一選択)
- 先天的要因(複数選択)
- 鼻の形(複数選択)
- 肌質(複数選択)
- 歯の特徴(複数選択)
- 笑顔の形(複数選択)
d. 機械学習モデルの生成
画像解析にあたって、Googleが提供する、事前にトレーニング済みな機械学習モデル「Cloud Vision API」を、可能な範囲で利用しますが、それだけでは解析・予測ができない項目が存在します。例えば、鼻が団子鼻か、矢印鼻か、などです。
それらは、独自の機械学習モデルを新たに開発することで対応したいと考えております。
一. 開発に必要なもの
- 機械学習モデルの作成アプリ「lobe」
- トレーニング用画像素材
二. 開発方法
- 「lobe」をMacパソコン上にインストールします。(無料)
- トレーニングに利用する画像を全て選択し、ドロップします。
- 画像を見て、手動でラベリング(タグ付け)を行なっていきます。
- 全ての画像のラベリングが完了したら、トレーニングデータをTensoflow.js形式でエクスポートします。
- エクスポートされたzipファイルをWEBRALまでご送付ください。
トレーニング方法
三. 機械学習モデルの評価方法
正しいモデル診断を行うにあたって、作成された機械学習モデルの性能が高い状態(予測結果が正しい状態)が望ましいですが、その性能を測るためには、生成された機械学習モデルを評価する必要があります。
機械学習教師あり学習における分類モデルの精度を示す上で一番基本となる指標が「正答率」です。
例えば、応募者の手の長さが「股下より下」「上」「同じ」を判別する機械学習モデルの正答率の計算方法は以下の通りで��す。
正答率(%) = 予測通り(予測結果も実行結果も「股下より下」or「上」「同じ」) / 全ての事象
例えば、正答率が95%以上であれば、機械学習モデルの性能は良しとし、95%を下回るようであれば再度トレーニング用の画像を増やしモデルの再生成を行う必要があります。
注記
性能評価のテストのために、登録済みの画像からランダムに20%が使われます。
例えば150枚画像が登録されていれば、30枚の画像がテスト用に使われます。なので、実際にトレーニングに使われる画像は120枚となります。