参加者
- PMS: 武田様、山森様、宮森様
- WEBRAL: 戸張、寺井
議題
1. 前回の決定事項やTODO
決定事項
採点ロジックを一部見直しつつ、引き続き学習データを増やして検証。
TODO
- 顔立ちの部分も減点方式に統一する
- グラフの部分の単位をポイントにして、「合計:111点 / 130点」の130点の部分を100点換算で表記する
- 150件でモデル作り直し&採点
- 目の形を3つに減らす。
- 吊り目と垂れ目を抽出して、送る。(ラベリングし直してもらう)
2. 検証結果
◼︎ SpreadSheet
https://docs.google.com/spreadsheets/d/1WGbnQb63f4uvGJ2anzs2IgbcWxGZ1dUGbaKR8lJLGLY/edit?usp=sharing
◼︎ 全体感
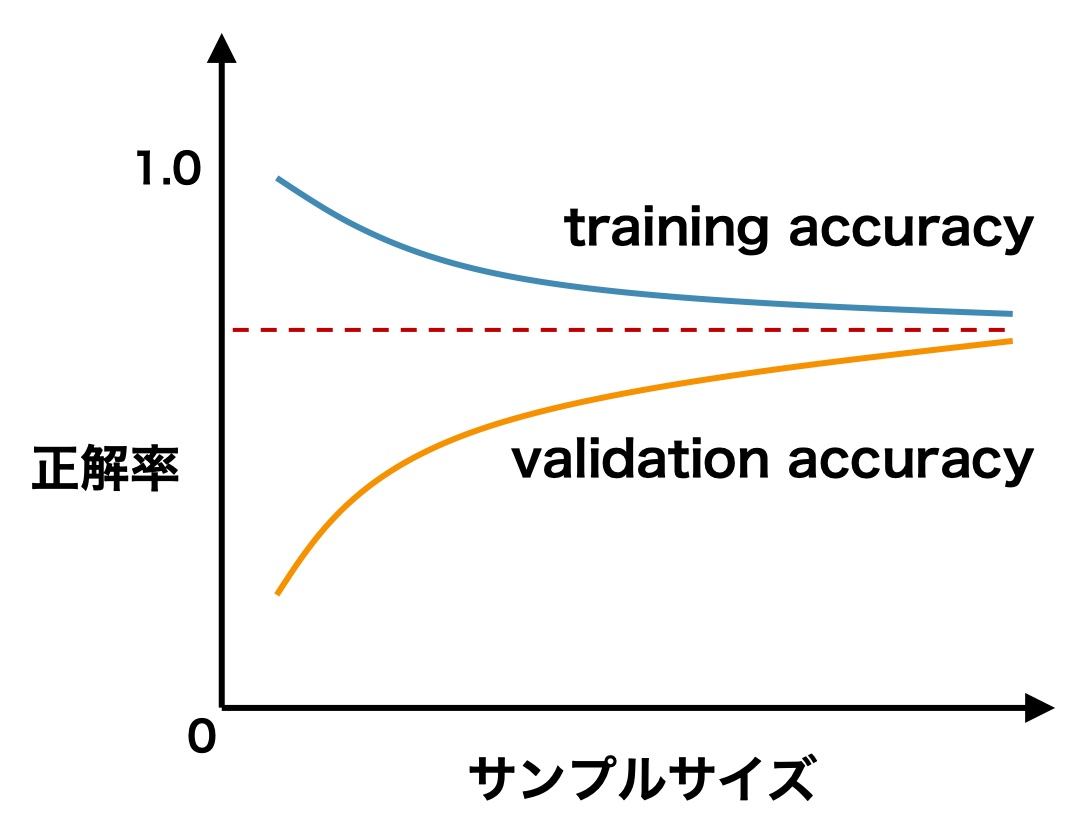
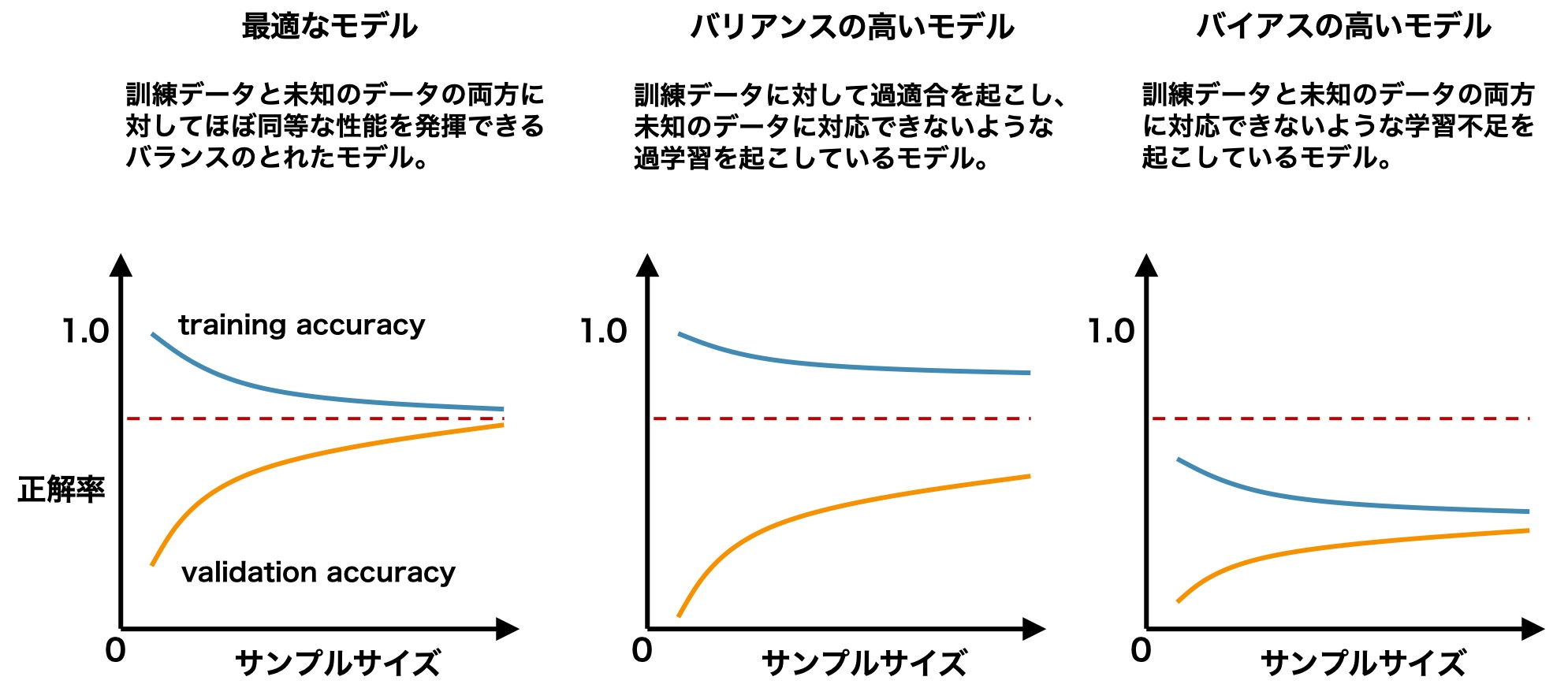
データに偏りがある&クラス(分類)の数が少ない項目は正答率(Accuracy)が高くなる傾向にあります。(例:目の特徴など)
◼︎ 対策
学習用データの少ないクラス(分類)のデータ量を増やす。 鼻の大きさであれば「小さい」のラベルのデータ量を増やす。 具体的には、各ラベル100枚分くらいまでにデータ量を増やす。
もし応募者の画像で足りなければ、フリー素材のデータセットを利用するなど。
https://www.kaggle.com/datasets/yewtsing/pretty-face https://www.kaggle.com/datasets/ciplab/real-and-fake-face-detection
・Accuracy
全クラス(分類)に対する予測精度の値(データ数の大きいクラスに対する予測精度の影響を受けやすい)・Precision
ある一つのクラス(分類)に対する予測精度の値
3. 全身写真のラベリングについて
前々回(2023年5月)の打ち合わせで、「脚の長さ」や「膝下の長さ」や「手の長さ」など全身写真のラベリングの正答率が上がりにくいという話がありました。 対応策として、全身写真の分類をやめて、すでに学習済みの全身の骨格を取得できる機械学習モデルを試してみるという案が出ました。
使ってみた結果
- https://webral.github.io/PoseNet-Sample/
- 足を閉じていると正確に測定できない
- 腰の位置が正確に測定しづらい
- あまり実用的ではない…?
4. おすすめの事務所について
- ファッションモデル系モデル事務所 => 19件
- コマーシャルモデル系モデル事務所 => 31件
◼︎「あなたにおすすめのモデル事務所」の選定フロー
- 応募者のラベルを元にコマーシャルモデルとしての点数とファッションモデルとしての点数を算出(採点表を元に)
- 8つのモデルカテゴリーの中から、応募者のレーダーチャートと最も形の近いモデルカテゴリーを一つ抽出(相関係数の高いものを一つ抽出) = 「あなたにおすすめのモデルカテゴリー」
- コマーシャルモデルかファッションモデルかを判定
- コマーシャルモデルだったら、コマーシャルモデル系のモデル事務所を全て抽出。ファッションモデルだったら、ファッションモデル系のモデル事務所を全て抽出。
- 抽出したモデル事務所の中から、応募者のレーダーチャートと形の近い(相関係数の高い)事務所順に並べる = 「あなたにおすすめのモデル事務所」
5. 本日の決定事項やTODO
- 各事務所のレーダーチャートをエクスポートして渡す
- 足を開いて写真を撮ってみる
- データ数が少ないラベルはどれか?を山森さんに送る