参加者
武田様、山森様、宮森様、戸張
議題
1. 前回の議論
全体的に山森さんの採点と機械学習による採点結果で乖離があり、特に「顔立ち」の採点結果が乖離が大きく、機械学習では低い点数が出てしまう問題
- [要因]
- 加点方式のため点数が上がりづらく、また「先天的要因」による減点が目立つ
- そもそも推論の精度が低い?
- [対応]
- 機械学習モデルのデータ量を増やし精度を高める
- 「顔立ち」に関する採点方法の見直し
2. 機械学習モデルの継続的な改善に向けた提案
- どれくらいデータを増やせばよいのか?
- 機械学習モデルの性能をどう高めていくのか?
- そもそも性能を評価するにはどうするのか?
- どういった流れで管理していくのか
についてのご説明と運用管理に関するご提案です。
2-1. モデル診断カルテで利用している機械学習モデルについて
Lobeを用いて生成した独自の機械学習モデルが約20個、稼働しています。
2-2. 機械学習モデルの一般的なライフサイクル
一般的に以下の1〜3のサイクルを繰り返し、モデルの性能を高め、管理します。
- データ準備
- モデル作成
- トレーニング
- モデル検証(評価)
- サービス運用
- サーバーへデプロイ
- 運用
- 監視
2-3. 機械学習モデルの性能評価の指標
運用している機械学習モデルのその時点での性能を判断するのに用いる指標には、精度(正解率)、適合率、再現率などがありますが、真かどうかを正確に判断したい場合に使える**精度(正解率)**により評価を行います。
例)目のタイプを分類する機械学習モデルの性能評価
例えば20件の検証用画像を予め人の目で分類し、その後機械学習モデルで推論を行い、それぞれの結果を比較します。答えが一致した件数が18件であれば、正答率は18/20×100=90%となります。
2-4. 必要なデータ数について
トレーニング用データを増やすことでモデルの性能を高めることが可能ですが、一方でどれほどの数のデータを増やせばいいのかはモデルにより様々であり、改善の余地があるのか?逆にこれ以上データを増やして性能は上がるのか?などを判断するのに役立つのが学習曲線です。
学習曲線は、縦軸に正答率、横軸にデータ数(サンプルサイズ)を取ります。
- 学習曲線
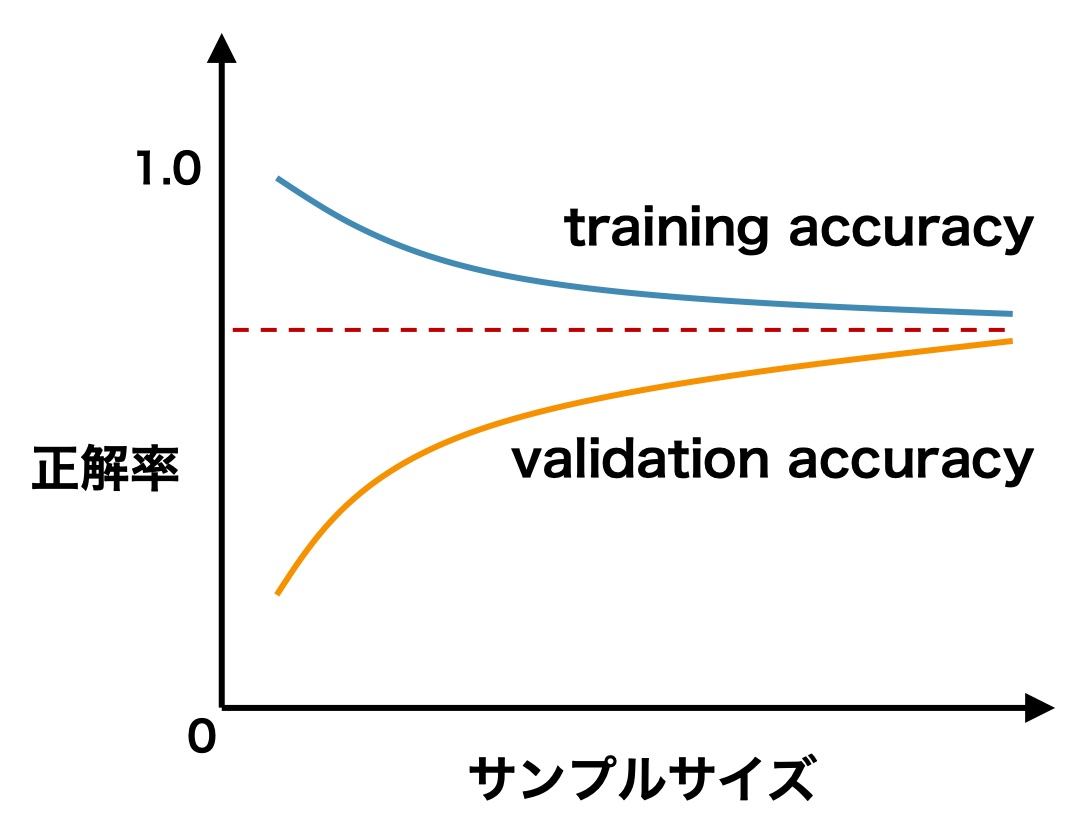
training accuracyは、トレーニングデータの推論精度。validation accuracyは、未知データに対する推論精度。
- モデルの状態
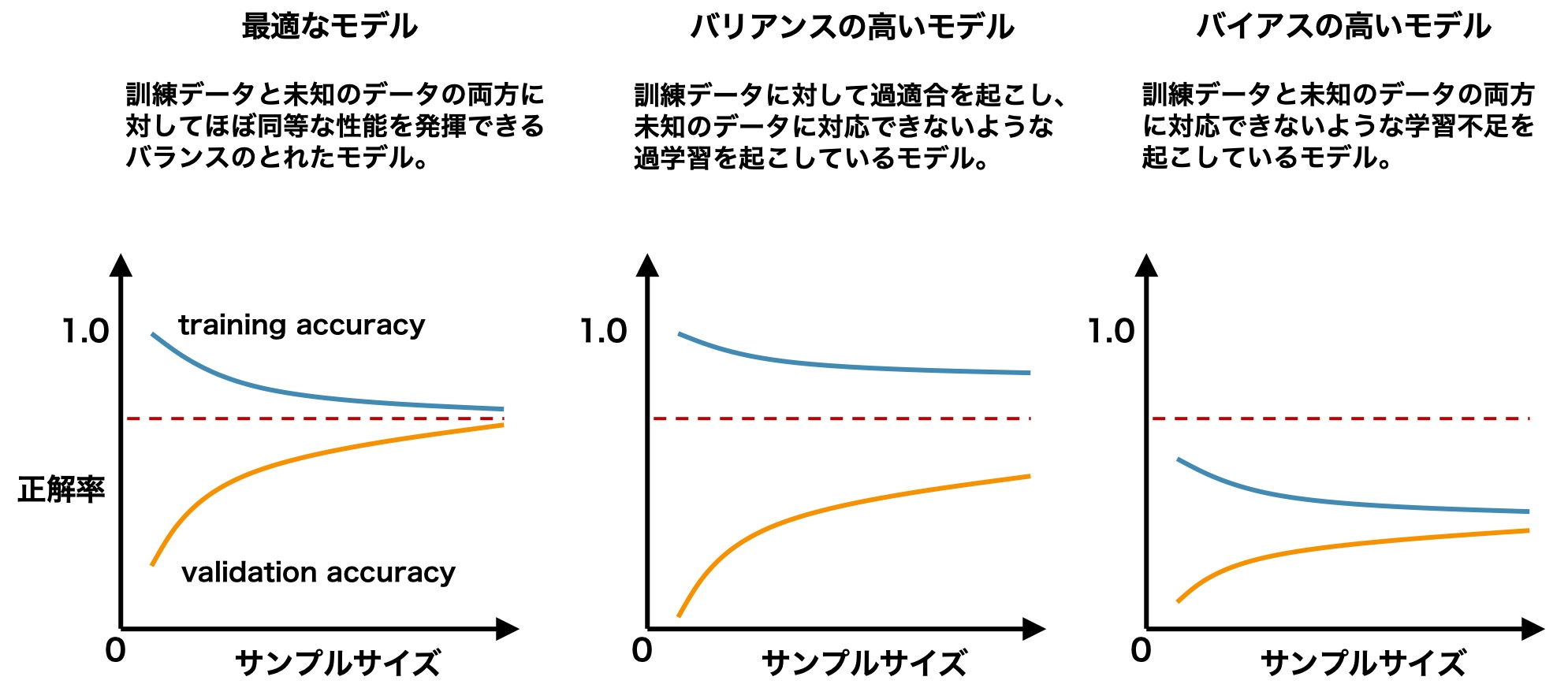
学習不足(高バイアス)状態への対応
- モデルの特徴量を増やす。アルゴリズム自体を変更するなどの対策が考えられます。
過学習状態への対応
- データを増やしトレーニングを行うことで解消されます。
いずれの状態にしても一旦データ量を増やし正答率をチェックすることで、現在の状況を把握することが必要です。
2-5. 具体的な運用フロー
上記の機械学習モデルの一般的なライフサイクルに則って運用を定期的に行います。
- 定期的に学習用データを集める
- データが集まったタイミングで交差検証(モデルの学習用に使うデータを、学習用に使う「訓練データ」とモデルの性能を評価のために使う「検証データ」の2つに分けることで過学習を防ぐ方法。一般的には訓練データ7 : 検証データ3の割合。)によりモデルのトレーニングを行います。
- Lobeで行うのではなく、WEBRAL側で用意する管理サイト上(最初はGoogle Drive)で画像のアップロードとラベリング作業を行なって頂きます。
- ラベリング作業完了次第、生成された各モデルの評価検証を管理サイト上(最初はスプレッドシート)で行います。(このタイミングでお打ち合わせ)
- お打ち合わせでは、各モデルの正答率の確認と改善が必要なモデルの洗い出しなどを行います。
- 生成された機械学習モデルをモデル診断カルテに反映します。
- 補足事項
- 機械学習モデル管理用ページを作成することで、ラベリング作業にのみ集中頂ける状況を作ります。
- 現在までにLobeでトレーニング頂いたものは一旦こちらに移行します。
2-6. 作業内容
- プロモデルスタジオ
- ラベリング作業(ただしLobeは使用せず、管理サイト上(最初はGoogle Drive)で行う)
- WEBRAL
- モデルの生成(最初はLobe。モデルの状況によって別のソフトを利用。)
- モデルの評価作業(最初はスプレッドシート)
- モデルのデプロイ(=モデル診断カルテに反映)
- お打ち合わせ
2-7. スケジュールと期間
- データが集まったタイミングで都度、上記のフローを実施。
2-8. 料金
要相談。都度作業時間に応じてご請求。
- 都度の作業時間イメージ
- モデルの生成・・・10〜20分×20モデル=約3〜4時間
- モデルの評価作業・・・10〜20分×20モデル=約3〜4時間
- モデルのデプロイ・・・3分×20モデル=約1時間
- お打ち合わせ・・・約1〜2時間
おおよそ5〜11時間 => 約3〜7.5万(税込)?